Arquitecturas Multi-Tenant
Un pequeño recorrido por los principales enfoques utilizados en este tipo de arquitecturas.
DIVULGACIÓNTIPSCLOUDARQUITECTURA
JLJuarez
11/12/20246 min read
Las arquitecturas multi-tenant son el modelo mas utilizado entre los proveedores de soluciones SaaS. En estos entornos, todos los clientes y sus usuarios consumen la misma solución y desde la misma plataforma tecnológica, mediante el intercambio de todos los componentes de la tecnología incluyendo el modelo de datos, servidores y las diferentes capas de base de datos.
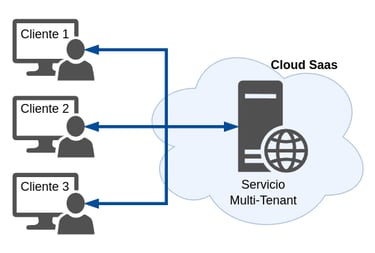
Las arquitecturas Multi-Tenant se basan en un principio de la arquitectura de software, donde una única instancia del software se ejecuta en un servidor y al servicio que este publica, se conectan múltiples clientes. Pero existe otra arquitectura de similares características, que es la arquitectura Multi-Instancia, la cual consiste en el despliegue de instancias independientes de software (o sistemas completos de hardware) que se establecen para cada uno de los distintos clientes.
Sin embargo nosotros nos centraremos en la arquitectura multi-tenant, aquí los componentes de software están diseñados para la partición de sus datos y la configuración personalizada, de manera que cada cliente pueda trabajar con una instancia de la aplicación configurada de forma determinada. Este tipo de arquitecturas permiten que sobre un único recurso operen múltiples usuarios que los dueños del mismo, por así decirlo.
Enfoques en la gestión de datos
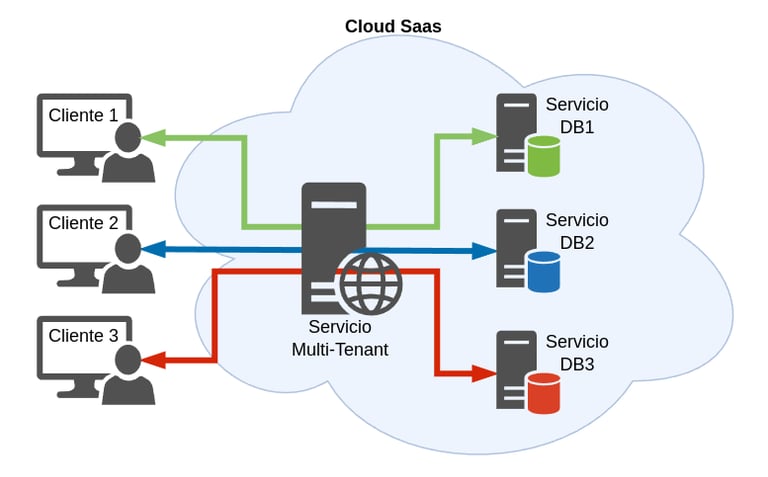
Bases de datos separadas
En este tipo de enfoque los datos de cada cliente se almacenan en bases de datos independientes para cada cliente. Las bases de datos pueden estar en el mismo servidor o pueden ser divididas a través de múltiples servidores de bases de datos. Este enfoque proporciona aislamiento máximo de los datos de los clientes.
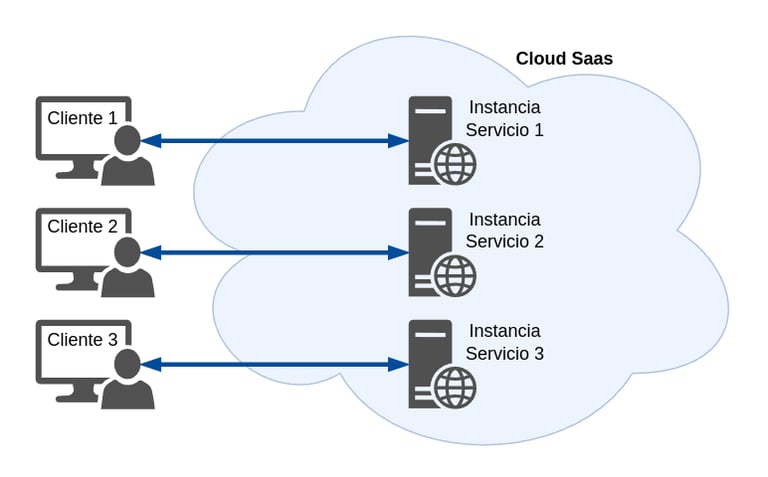
Recursos informáticos y código de aplicación generalmente son compartidos entre todos los Clientes en un servidor, pero cada cliente tiene su propio conjunto de datos que se mantiene lógicamente aislado del resto de datos que pertenece a los otros clientes. Los meta-datos asociados a cada base de datos, junto con los del cliente correspondiente, sumado a la configuración de seguridad aplicada a la base de datos, impide que cualquier cliente de forma accidental o malintencionada pueda acceder a los datos de otro.
Dotar a cada cliente de su propia base de datos, hace que sea fácil de extender la aplicación del modelo de datos para satisfacer las necesidades de los clientes individuales, por otro lado la restauración de copias de seguridad de los datos de un cliente se convierte en un proceso relativamente simple.
Por desgracia, este enfoque tiende a conducir a mayores costos de mantenimiento del equipo de mantenimiento, así como también los costes de hardware son también más altos, ya que generalmente están bajo distintos criterios de explotación.
Consideraciones:
El tiempo de desarrollo: El modelo de servidor independiente requiere más tiempo de desarrollo mínimo en comparación con una solución de arquitectura estándar.
Costos de hardware: Esta es la arquitectura más cara, ya que cada cliente requiere su propio servidor de hardware, además de todo lo relacionado con su mantenimiento y ciclo de vida.
Aplicación y el rendimiento de base de datos: Por lo general esta arquitectura tiene el rendimiento más predecible, porque este no se ve afectado por el de otro cliente.
Seguridad: Debido al total aislamiento de otros clientes, los datos de cada cliente corren menor riesgo de accesos indebidos desde la propia plataforma, ya que se aplican reglas individualizadas.
Requisitos de personalización: Cada cliente tiene su propia base de datos, por lo que es más fácil de personalizar.
El número de clientes: Este enfoque hace que sea mucho más difícil de manejar un gran número de clientes.
Bases de datos compartidas y Esquemas separados
Este enfoque consiste en arrendatarios de viviendas múltiples en la misma base de datos, con cada cliente que tiene su propio conjunto de tablas que se agrupan en un esquema creado específicamente para el cliente. Con este enfoque puede tener una sola base de datos con un esquema para cada cliente.
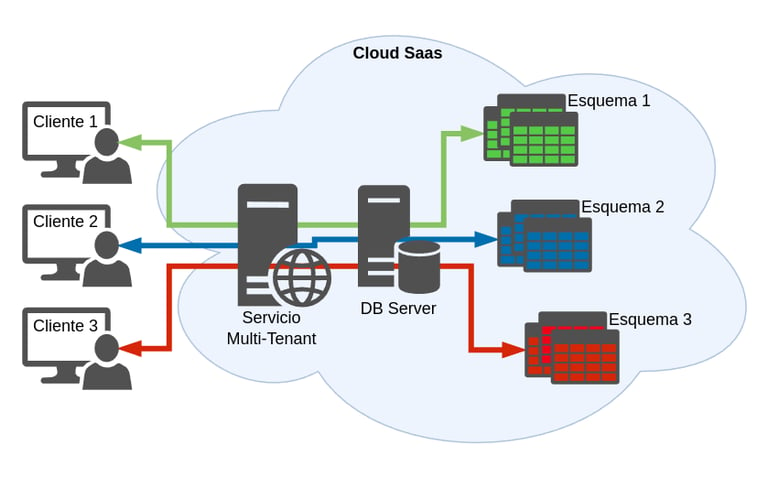
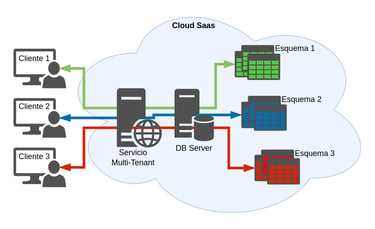
Consideraciones:
Aplicación y el rendimiento de base de datos: El rendimiento de un cliente puede verse afectado por las actividades de los otros clientes que comparten el servidor.
Seguridad: El DBMS debe asegurar que la estructura de permisos es tal, que cada esquema de datos sólo está disponible para usuarios autorizados, asegurándose de seleccionar o restringir el esquema al que se accede por cada usuario.
Requisitos de personalización: Cada cliente tiene su propio esquema, así que es fácil de personalizar para las diferentes necesidades de cada cliente.
El número de clientes: Este modelo es capaz de manejar más clientes que los modelos de bases de datos separadas, pero todavía requieren una cierta cantidad de la administración. La migración de los clientes a una base de datos independiente puede ser un desafío en función de las utilidades que ofrezca el DBMS.
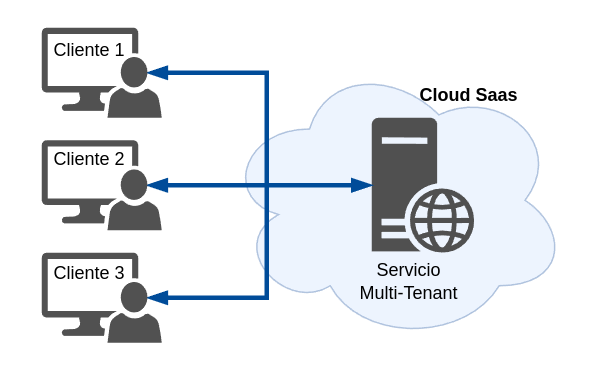
Bases de datos compartidas y Esquemas compartidos
Aquí sólo tenemos una única base de datos y un esquema único. En este enfoque, todos los clientes comparten el mismo conjunto de tablas, aunque se asigna un ID de cada cliente asociados con los registros de su propiedad.
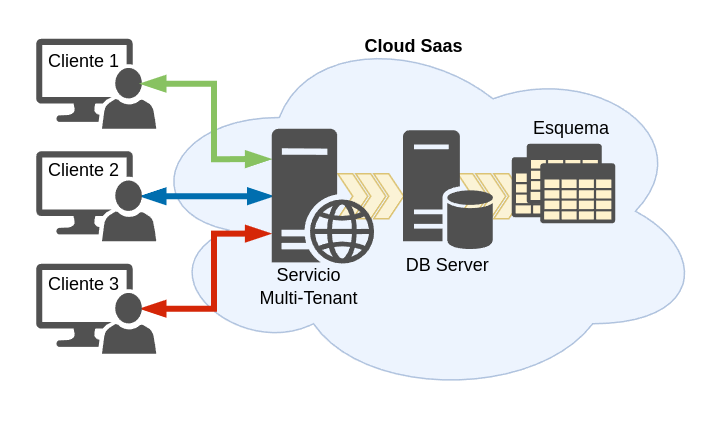
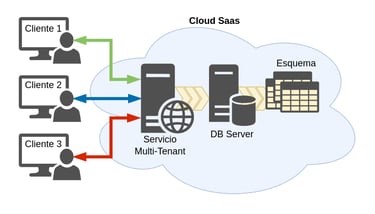
De los tres enfoques explicados, este tiene los más bajos costos de hardware y de mantenimiento, ya que le permite servir al mayor número de clientes por base de datos del servidor. Sin embargo, debido a que múltiples clientes comparten la misma base de datos y tablas, es un enfoque que incurre en un mayor esfuerzo de desarrollo en el ámbito de la seguridad, ya que ha de garantizar que los clientes no pueden acceder a los datos de otros, incluso en el caso de que aparezcan errores inesperados o ataques.
El procedimiento para restaurar los datos de un cliente es similar a la del enfoque de esquema común, pero con la complicación adicional de que al tratarse de filas individuales, en la base de datos de producción es necesario hacer uso de una base de datos temporal, con el objetivo de mantener la integridad en los procesos de eliminación e inserción. Si hay un número muy grande de filas en las tablas afectadas, esto puede afectar el rendimiento notablemente para todos los clientes que utilizan la base de datos.
El enfoque de esquema compartido es apropiado cuando es importante que el servicio sea capaz de servir a un gran número de clientes con un pequeño número de servidores y que ademas los clientes potenciales estén dispuestos a renunciar a un mayor aislamiento a cambio del bajo coste que este tipo de enfoque proporciona.
Consideraciones:
Aplicación y rendimiento de la base de datos: El rendimiento de un cliente puede verse afectado por las actividades de los otros clientes. El rendimiento de las consultas tendrán que ser examinados cuidadosamente para garantizar que existen los índices adecuados.
Seguridad: Los componentes deben utilizar código de consultas especialmente diseñado para seleccionar y restringir los datos accedidos, garantizando que solo pertenecen al cliente correcto. Es imprescindible hacer pruebas sólidas para garantizar que un usuario no es capaz de ver los datos de los otros clientes.
Requisitos de personalización: Todos los clientes comparten el esquema, por lo que es mucho más difícil permitir la garantizar la personalización. Hay una variedad de enfoques que se pueden utilizar para proporcionar personalización del modelo de datos. El nivel de complejidad de los componentes necesarios se dispara con cada petición
El número de Clientes: Este modelo es capaz de manejar más muchos clientes que los modelos anteriores. La migración de los clientes que requieren un mejor rendimiento o la capacidad puede ser un reto, ya que los datos tendrán que ser extraídos de cada caso en operaciones separadas, para re-alojarlos en otros servidores.
Consideraciones finales
Como hemos visto hay diferentes planteamientos de cara a la estructura y explotación que podemos dar a los datos que ha de manejar nuestra solución. No hay planteamientos malos o buenos, mas bien deberíamos verlo como mas o menos adecuados a nuestra solución, presupuesto y en general a los requisitos que tengamos.
Lo mas importante es tener claro el impacto de nuestra decisión, ya que determinara el modelo de desarrollo, despliegue y mantenimiento que debemos aplicar y por tanto como se verán directamente afectados los costes de dicha solución.
Historias de un Tech Lead
Reflexiones sobre arquitectura, desarrollo de software y otras cosas.
© 2026. All rights reserved.
NOTA:
Si, ya lo se, casi todas las imágenes contenidas en este blog, han sido y posiblemente serán generadas por IA, por desgracia no dispongo de capacidades artísticas adecuadas y mucho menos de tiempo para buscar imágenes adecuadas en la red. Por lo que muy pocas serán creadas por mi directamente.