Almacenamiento distribuido y sincronizado
Una pequeña comparativa entre dos soluciones de almacenamiento distribuido.
DIVULGACIÓNDISEÑOPROYECTOSARQUITECTURATECNOLOGIAS
JLJuarez
6/9/20259 min read
Hace algunos años colabore en un proyecto en el que era necesario diseñar un sistema de almacenamiento en red y que a la vez fuese capaz de mantener sincronía, integridad y el máximo de velocidad posible en sus procesos y que ademas mantuviese máxima compatibilidad con Docker.
Como de costumbre me puse a investigar y buscar posibles productos y herramientas útiles para montar una solución que cumpliese con el máximo numero de los requisitos solicitados, finalmente prepare la presentación de dos posibilidades que os relatare mas adelante. Por razones que solo los adivinos conocen, al final la solución presentada al cliente fue otra que no cumplía todos los requisitos y como era de esperar perdimos el cliente, pero eso es otra película que si hay ocasión os contare en otro momento.
Contexto
Vamos al turrón, la mayoría de soluciones o sistemas que desplegamos necesitan almacenamiento para recursos de múltiple tipologia, como pueden ser imágenes, ficheros de configuración, documentos, etc. En el caso que nos ocupa, la solución ademas debe cumplir con los requisitos comentados al principio.
En condiciones normales los servicios y aplicaciones residentes en una maquina, solo tendrán acceso al almacenamiento existente en la misma máquina. Si tenemos aplicaciones alojadas en las dos maquinas y deben tratar con la misma información, tendremos un problema de inconsistencia en los datos que han de compartir y nos obligará a montar algún sistema de sincronización entre las dos maquinas, vamos lo que viene siendo un cluster y todos sabemos lo que eso acarrea.
Si a todo lo anterior le añadimos un condimento mas, como pueden ser que nuestras aplicaciones estén desplegadas mediante contenedores Docker, se nos plantea la necesidad de contar con un posible dimensionamiento horizontal, para atender los requerimientos de los contenedores cliente. Ademas, dependiendo de como diseñemos el cluster, este tendrá que compartir recursos de CPU y Memoria entre el sub-sistema de procesos y el de gestión del sistema de archivos, lo que ocasionara una posible perdida de rendimiento de la solución.
La investigación inicial
Como en todo proyecto que se precie, sobre todo si no se es un experto en la materia a tratar, lo primero es realizar una buena investigación en busca de posibles soluciones existentes, herramientas que nos ayuden o guíen en alcanzar la solución.
Lo primero que hice fue busca información sobre los sistemas de ficheros en red disponibles actualmente, lo que me arrojo una lista considerable:
NFS (Network File System): Protocolo ampliamente usado, especialmente en sistemas Unix y Linux. Permite compartir directorios entre máquinas en una red.
SMB/CIFS (Server Message Block/Common Internet File System): Usado principalmente en sistemas Windows, pero también disponible en Linux y macOS. Permite compartir archivos e impresoras en redes locales.
AFS (Andrew File System): Sistema de archivos distribuido que permite acceder a datos en múltiples servidores. Usado en entornos académicos y científicos.
GlusterFS: Sistema de archivos distribuido que permite el almacenamiento en red escalable. Popular en entornos de grandes volúmenes de datos y en la nube.
CephFS: Parte del ecosistema Ceph, es un sistema de archivos distribuido diseñado para ser altamente escalable y resistente, utilizado en soluciones de almacenamiento en la nube.
HDFS (Hadoop Distributed File System): Desarrollado como parte del proyecto Apache Hadoop, está optimizado para almacenar grandes cantidades de datos distribuidos y es común en entornos de big data.
Lustre: Sistema de ficheros de alto rendimiento, usado en entornos de supercomputación y almacenamiento masivo, como en servidores de cálculo intensivo.
BeeGFS: Diseñado para alto rendimiento y escalabilidad, usado en clústeres HPC (computación de alto rendimiento).
iSCSI (Internet Small Computer Systems Interface): Aunque no es un sistema de archivos en sí, iSCSI permite el acceso a dispositivos de almacenamiento a través de redes IP, funcionando como una base para sistemas de ficheros distribuidos.
MooseFS: Sistema distribuido que permite almacenamiento a gran escala, con tolerancia a fallos y almacenamiento replicado.
Después de una revisión transversal de la información técnica de cada uno de ellos y lo que podían aportar en cada caso a nuestro proyecto, decidí centrarme en NFS y GlusterFS, ya que ademas de cumplir con casi todos los requisitos de nuestros proyecto, resultaban ser los mas sencillos de aplicar, los que tenían mas éxito entre las comunidades de expertos y también los mas ajustados en recursos.
Posibles soluciones.
Una vez seleccionadas las tecnologías a utilizar, disponíamos de dos formas de aplicarlas, apoyándonos directamente el S.O. o haciendo lo propio directamente con Docker, la lógica dicto que debíamos utilizar la segunda, ya que Docker dispone de controladores nativos para los sistemas de ficheros que pretendíamos utilizar y ademas nuestras aplicaciones utilizaban como entorno de ejecución Docker, por lo que no cabían discusiones.
Una de las ventajas palpables que obteníamos con estos sistemas de archivos, era que al separar el sistema de proceso del almacenamiento, nuestras aplicaciones no tendrán que competir por los recursos de CPU contra el sistema de ficheros, algo muy importante en sistemas que han de atender gran volumen de peticiones.
Una vez realizadas las POC para cada caso y extraídos los datos necesarios para su evaluación, sacamos las siguientes conclusiones.
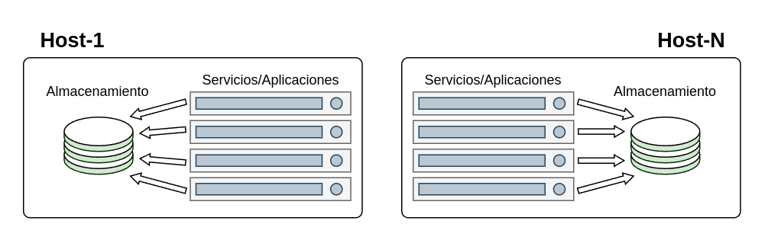
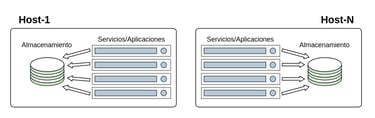
El caso NFS
Este tipo de solución nos proporcionara un sistema de almacenamiento centralizado y compartido con los host y aplicaciones/servicios implicados, quedando un despliegue similar al de la imagen.
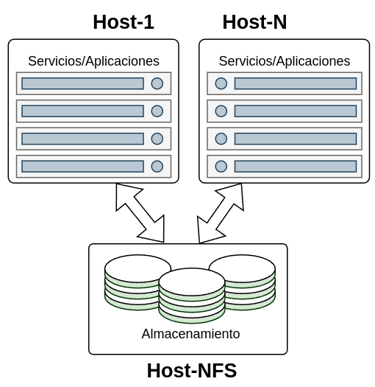
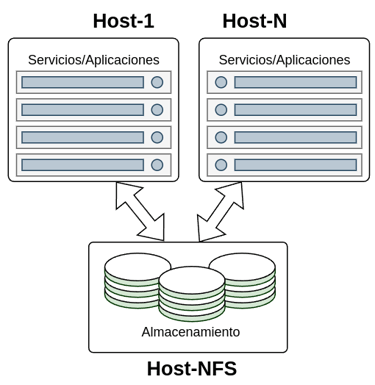
Como se observa en la imagen el despliegue se compone de varias maquinas, unas las que albergan los contenedores con los servicios que consumirán el almacenamiento y otra encargada de los contenedores con los servicios NFS que compartirán el almacenamiento.
Pros:
Centralización del almacenamiento: Permite que múltiples contenedores (incluso en diferentes hosts Docker) accedan a los mismos datos desde una ubicación centralizada. Esto es ideal para aplicaciones distribuidas, clústeres de Docker Swarm, o Kubernetes.
Persistencia de datos externa: Los datos no residen en el host Docker local, lo que facilita el reemplazo o la actualización de hosts Docker sin perder datos críticos de los contenedores.
Facilidad de gestión: Una vez que el servidor NFS está configurado, la gestión del almacenamiento se realiza a nivel del servidor NFS, lo que puede simplificar las copias de seguridad, el dimensionamiento y la administración de permisos para todos los contenedores que lo utilizan.
Compartición de datos: Contenedores de diferentes servicios o aplicaciones pueden compartir un conjunto común de datos, lo que es útil para escenarios donde los datos necesitan ser procesados por múltiples componentes.
Tecnología madura: NFS es un protocolo de sistema de archivos de red muy maduro y bien comprendido, con muchas herramientas y experiencia disponible.
Flexibilidad de ubicación: El servidor NFS puede estar en cualquier lugar de la red, lo que ofrece flexibilidad para la arquitectura de tu infraestructura.
Contras:
Dependencia de la red: El rendimiento y la disponibilidad del almacenamiento dependen directamente de la latencia y el ancho de banda de la red entre el host Docker y el servidor NFS. Un problema de red puede afectar drásticamente a todos los contenedores que usan ese volumen.
Complejidad de configuración inicial: Configurar un servidor NFS y asegurar los permisos correctos puede ser más complejo que simplemente usar volúmenes locales o bind mounts.
Rendimiento: Generalmente, NFS no ofrece el mismo rendimiento de E/S que el almacenamiento local. Esto puede ser un cuello de botella para aplicaciones con alta demanda de lectura/escritura de disco.
Single Point of Failure (SPOF) - Punto Único de Fallo: El servidor NFS puede convertirse en un punto único de fallo. Si el servidor NFS falla, todos los contenedores que dependen de él dejarán de funcionar o experimentarán errores. Las configuraciones de alta disponibilidad para NFS son más complejas.
Gestión de UID/GID: La gestión de usuarios y grupos (UID/GID) entre el contenedor, el host Docker y el servidor NFS puede ser complicada. Si los UID/GID no coinciden, pueden surgir problemas de permisos al acceder a los archivos.
Seguridad: NFS, especialmente en sus versiones más antiguas (NFSv3), puede tener deficiencias de seguridad inherentes. Es crucial configurarlo de forma segura, posiblemente con firewalls y autenticación adecuada, y considerar NFSv4 para características de seguridad mejoradas.
Overhead de protocolo: El protocolo NFS añade un pequeño overhead a cada operación de E/S, lo que puede impactar el rendimiento en comparación con el acceso directo al disco.
El caso Glusterfs
En este caso podemos ir un paso más allá, ya que esta solución nos permite disponer de nodos de almacenamiento que se pueden ir añadiendo, lo que nos permite que el almacenamiento también pueda escalar horizontalmente, quedando un despliegue como el de la imagen.
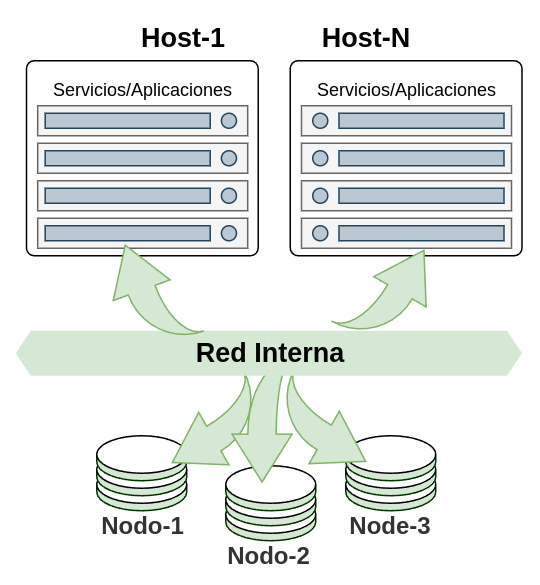
Pros:
Alta disponibilidad y redundancia: Con volúmenes replicados, los datos están distribuidos y replicados entre múltiples nodos. Si un nodo falla, los datos siguen siendo accesibles desde los otros nodos, lo que proporciona resiliencia y alta disponibilidad.
Escalabilidad horizontal: GlusterFS está diseñado para escalar horizontalmente añadiendo más nodos ("bricks") al clúster, permitiendo aumentar tanto la capacidad de almacenamiento como el rendimiento.
Persistencia de datos distribuida: Permite que los contenedores accedan a datos persistentes que no están vinculados a un único host Docker. Esto es crucial para aplicaciones distribuidas y orquestadores como Docker Swarm o Kubernetes.
Software de código abierto y gratuito: GlusterFS es de código abierto, lo que reduce los costos de licencia.
Flexibilidad de volumen: Soporta diferentes tipos de volúmenes (replicados, distribuidos, distribuidos-replicados, etc.) que se pueden adaptar a diferentes necesidades de rendimiento y redundancia.
No hay metaserver central: A diferencia de algunos otros sistemas de archivos distribuidos, GlusterFS no tiene un único punto de fallo de metadatos, lo que mejora la resiliencia.
Contras:
Complejidad de configuración y gestión: Configurar un clúster GlusterFS, incluyendo la gestión de "peers", volúmenes y firewalls, es significativamente más complejo que un simple montaje NFS o un volumen local.
Rendimiento en ciertas cargas de trabajo: Aunque GlusterFS es bueno para cargas de trabajo distribuidas y archivos grandes, el rendimiento puede no ser óptimo para operaciones de E/S de archivos pequeños y acceso concurrente muy alto, donde los sistemas de archivos locales o de bloque pueden ser superiores. La latencia de red es un factor.
Dependencia de la red: Como todo sistema de archivos de red, el rendimiento y la estabilidad están intrínsecamente ligados a la calidad y velocidad de la red subyacente.
Gestión de UID/GID: Al igual que con NFS, la sincronización de UID/GID entre los contenedores, el host y los servidores GlusterFS puede ser un desafío y requiere una planificación cuidadosa para evitar problemas de permisos.
Curva de aprendizaje: Requiere una comprensión de los conceptos de sistemas de archivos distribuidos y la terminología de GlusterFS.
Debugging: Cuando surgen problemas, diagnosticar y resolverlos en un sistema de archivos distribuido puede ser más difícil debido a la complejidad de la interacción entre múltiples nodos.
Consumo de recursos: Los nodos GlusterFS consumirán recursos (CPU, RAM, disco) para operar el servicio de almacenamiento distribuido, lo que debe tenerse en cuenta en la planificación de la capacidad.
Conclusiones
Como veis son dos soluciones casi antagónicas con un fin común, hacer que los datos estén disponibles para varios servicios separados entre si y con un mismo propósito. Cada una tiene sus ventajas y desventajas, incluso siendo puristas podríamos asegurar que alguna cumple mejor con los requisitos iniciales que se solicitaron.
Yo particularmente para el caso que necesitábamos cubrir, defendí la solución con GlusterFS, ya que cumplía casi totalmente con los requisitos previstos, aunque como comente al principio al final se opto por otra solución.
En cualquier caso, quiero resaltar algunos puntos importantes a tener en cuenta, mas allá de las tecnologías utilizadas y que siempre debemos considerar antes de llevar cualquiera de las soluciones de este tipo a producción:
Es muy importante implementar la seguridad de los recursos compartidos, algo imprescindible para aislar el acceso al sistema de almacenamiento.
Anteponer seguridad perimetral de forma que solo permita el trafico por los puertos indicados, en el sentido deseado y por los elementos adecuados.
Implementar un sistema de monitorización adecuado para controlar de la forma mas completa el estado y funcionamiento de la solución.
Por supuesto implementar un sistema de backup para el almacenamiento y así cubrirnos ante una situación de desastre.
Por ultimo debemos tener en cuenta que el almacenamiento puede consistir en un volumen contenedor o un filesystem montado directamente desde el hots. Esto en términos generales y a primera vista no debería afectar al funcionamiento de la solución, pero lo que si cambiara es el modo del que vamos a gestionar dicho almacenamiento, ya que cada implementación tiene requisitos diferentes.
Historias de un Tech Lead
Reflexiones sobre arquitectura, desarrollo de software y otras cosas.
© 2026. All rights reserved.
NOTA:
Si, ya lo se, casi todas las imágenes contenidas en este blog, han sido y posiblemente serán generadas por IA, por desgracia no dispongo de capacidades artísticas adecuadas y mucho menos de tiempo para buscar imágenes adecuadas en la red. Por lo que muy pocas serán creadas por mi directamente.